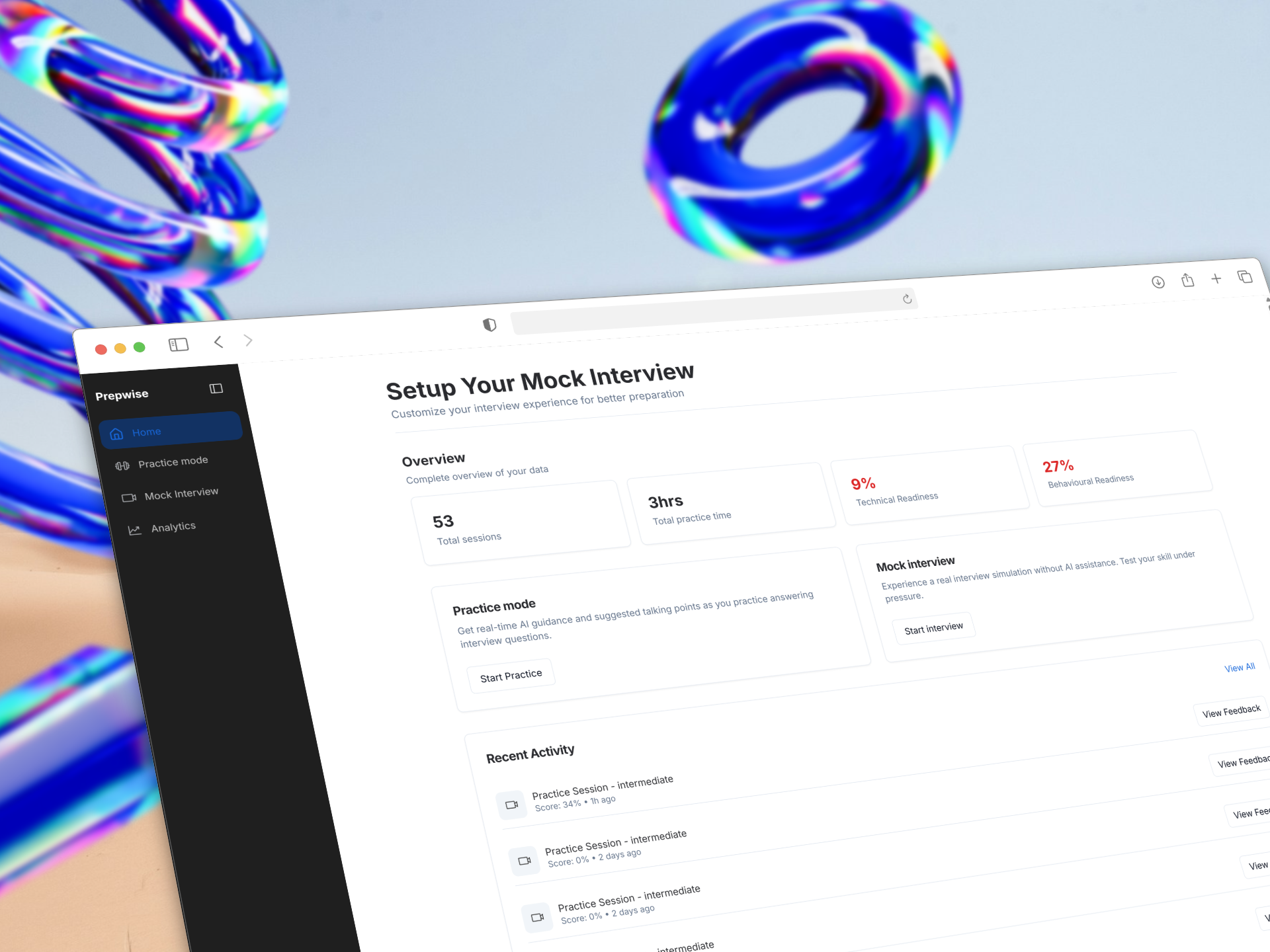
About the Project
Prepwise came out of Collabsprint, a sprint program that pairs engineers with product designers, product managers, and industry mentors to ship a real product in 8 weeks. I was the fullstack AI engineer on a team of 4: 2 engineers, 1 product manager, and 1 designer, with guidance from mentors at IBM, Amazon, and Bank of America who helped shape the system thinking behind the product. My job was to translate that into a system that felt like sitting across from a senior interviewer instead of staring at a chatbot.
I owned the full backend (13 REST endpoints), the real-time GPT-to-TTS streaming pipeline, the WebRTC avatar integration, and the evaluation engine. The hardest problem was latency. GPT takes 1–2 seconds to generate feedback, Cartesia Sonic-3 takes another 1–2 seconds to synthesise voice, and a Simli lip-synced avatar needs PCM16 audio at 16kHz in 960-byte chunks over WebRTC. Doing any of that sequentially gave users 3–4 seconds of dead silence. So I built a token-level streaming pipeline: Vercel AI SDK pipes GPT tokens into Cartesia's WebSocket as they generate, Cartesia streams back PCM audio chunks, the browser decodes and plays them via Web Audio API while simultaneously downsampling to 16kHz and feeding them to Simli over WebRTC for real-time lip sync. Time-to-first-audio dropped from 3–4 seconds to ~300–500ms. Every external service has a fallback — if Simli can't connect in 4 seconds, the app degrades to audio-only. If OpenAI is down, a keyword-matching scorer takes over. The app degrades gracefully but never breaks.
What I Built
- ▸Full backend API (13 REST endpoints) with JWT middleware auth
- ▸Real-time GPT → Cartesia TTS streaming pipeline — ~300ms time-to-first-audio
- ▸WebRTC Simli lip-synced avatar with 24kHz → 16kHz real-time downsampling
- ▸GPT-4o-mini evaluation engine with Zod schema enforcement + NDJSON streaming
- ▸Multi-dimensional scoring: Relevance, Coverage, Clarity, Depth (25 pts each)
- ▸Server-side interview state machine — stateless client, cheat-proof
- ▸Graceful fallbacks — keyword scorer if OpenAI fails, audio-only if Simli fails
System Design
Next.js 14 App Router runs the full stack — 13 REST endpoints, React frontend, and Vercel serverless deployment in one codebase. Auth is JWT in HTTP-only cookies verified at the Next.js middleware layer (edge-compatible via jose), with bcrypt-hashed passwords. The real-time feedback pipeline uses Vercel AI SDK's streamText() to pipe GPT-4o-mini tokens into Cartesia's WebSocket as they generate, buffering at ~60 character phrase boundaries before flushing. Cartesia returns base64 PCM16 audio chunks that get enqueued into a ReadableStream and streamed chunked back to the browser. On the client, a downsampler converts 24kHz → 16kHz via linear interpolation and splits the stream into the exact 960-byte chunks Simli's WebRTC channel expects for real-time lip sync. Evaluation uses GPT-4o-mini with Zod schemas enforcing structured output, streamed as NDJSON so the client renders sub-scores progressively. Interview state lives entirely server-side as a strict state machine in MongoDB Atlas — the client is stateless, which prevents cheating and eliminates a whole class of bugs.
Tech Stack
- Next.js 14
- TypeScript
- Vercel AI SDK
- GPT-4o-mini
- Cartesia Sonic-3
- Simli
- WebRTC
- MongoDB
- Zod
- jose JWT